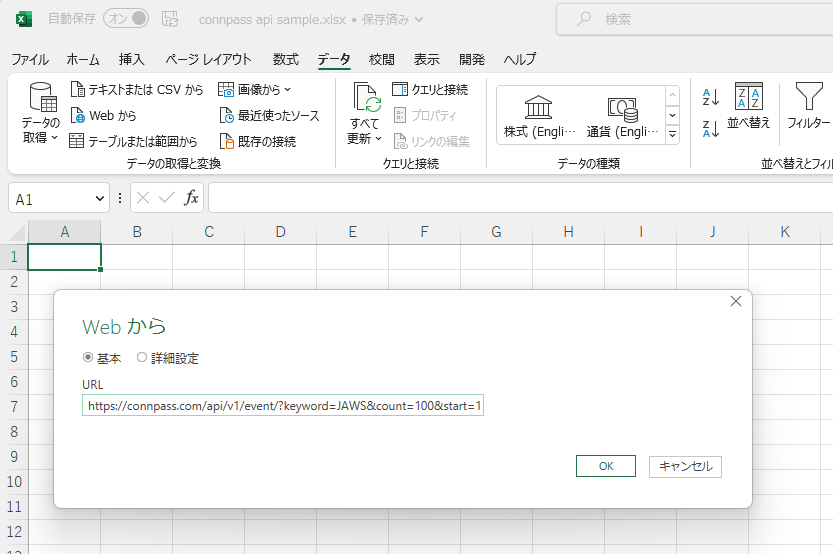
概要
このドキュメントは、Power BI Desktop と Power BI サービスで外部API(connpass API v2、Doorkeeper API)を使ってデータを取得・加工する際に学んだことをまとめたものです。
1. M言語の基本ルール
変数名のルール
- 数字から始まる変数名は使えない
- ❌
90日前 = ... - ✅
過去90日 = ...
- ❌
- スペースを含む場合は
#"..."で囲む - 日本語の変数名は使用可能
関数の引数名と外側の変数名の衝突に注意
// ❌ 引数名 subdomain が外側の Query フィールド名と衝突する
GetLatestEvent = (subdomain as text) =>
Web.Contents(..., [Query=[subdomain = subdomain]])
// ✅ 引数名を sd に変更して衝突を回避
GetLatestEvent = (sd as text) =>
Web.Contents(..., [Query=[subdomain = sd]])2. Power BI サービスでの動的クエリの制限
問題
Power BI サービスでは、URLを動的に生成するクエリ(動的データソース)は自動更新できない。
解決策:Query=[] オプションを使う
// ❌ 動的URLとみなされ更新不可
ソース = Web.Contents("https://api.example.com/events?" & "subdomain=" & P1)
// ✅ Query=[] オプションを使うことで更新可能
ソース = Web.Contents(
"https://api.example.com/events/",
[
Query=[subdomain = P1, count = "100"]
]
)重要:Text.Combine も動的とみなされる場合がある
ベースURLは固定の文字列にして、パラメーターは Query=[] に渡す。
3. Power BI サービスでの外部API認証設定
問題
ヘッダーにAPIキーを渡す方式の外部APIは、Power BI サービスの資格情報設定で「匿名」認証が拒否される場合がある。
解決策
資格情報設定画面で以下のように設定する:
| 設定項目 | 値 |
|---|---|
| 認証方法 | 匿名 |
| プライバシーレベル | Public |
| テスト接続をスキップする | ✅ チェックを入れる ← これが重要! |
APIキーはヘッダーで渡す
ソース = Json.Document(Web.Contents(
"https://api.example.com/events/",
[
Headers=[#"X-API-Key"= "YOUR_API_KEY"],
Query=[subdomain = P1, count = "100"]
]
))4. 並列読み込みの無効化
複数のクエリが同時にAPIを叩くと、アクセス制限(429 Too Many Requests)に引っかかる。
設定方法
- 「ファイル」→「オプションと設定」→「オプション」
- 「現在のファイル」→「データの読み込み」
- 「テーブルの並列読み込み」→「同時ジョブの最大数」
- 「1(並列読み込みを無効にする)」を選択
5. APIのアクセス制限回避:Function.InvokeAfter
APIに1秒間に1リクエストの制限がある場合、Function.InvokeAfter で待機時間を入れる。
GetLatestEvent = (sd as text) as record =>
Function.InvokeAfter(
() =>
let
response = try Json.Document(Web.Contents(
"https://api.example.com/events/",
[
Headers=[#"X-API-Key"= "YOUR_API_KEY"],
Query=[subdomain = sd, count = "1", order = "2"]
]
)),
結果 = if response[HasError] then
[最新イベント日 = null, 最新イベントタイトル = "APIエラー: " & response[Error][Message]]
else if response[Value][results_available] = 0 then
[最新イベント日 = null, 最新イベントタイトル = "イベントなし"]
else
[
最新イベント日 = response[Value][events]{0}[started_at],
最新イベントタイトル = response[Value][events]{0}[title]
]
in
結果,
#duration(0, 0, 0, 1.2) // 1.2秒待機
),待機時間の目安
| 待機時間 | 特徴 |
|---|---|
| 1.0秒 | API制限ギリギリ |
| 1.2秒 | 適度な余裕で安全 ✅ |
| 1.5秒 | より安全だが処理時間が長い |
6. エラーハンドリング
try...otherwise パターンで途中エラーでも処理を止めない。
response = try Json.Document(Web.Contents(...)),
結果 = if response[HasError] then
[最新イベント日 = null, 最新イベントタイトル = "APIエラー: " & response[Error][Message]]
else if response[Value][results_available] = 0 then
[最新イベント日 = null, 最新イベントタイトル = "イベントなし"]
else
[
最新イベント日 = response[Value][events]{0}[started_at],
最新イベントタイトル = response[Value][events]{0}[title]
]7. SubdomainList の管理
複数のクエリで共通して使うサブドメインリストは、別クエリ(SubdomainList)として管理して参照する。
// SubdomainList クエリ
let
Subdomains = {
"subdomain-1",
"subdomain-2",
"subdomain-3"
// ...
},
クリーン済み = List.Transform(Subdomains, each Text.Clean(Text.Trim(_)))
in
クリーン済み注意:Power BI サービス(Dataflow Gen1)での制限
Dataflow Gen1 では他のクエリを参照する「計算されたテーブル」は Premium ライセンスが必要。Power BI Pro では使えない。
→ 解決策:SubdomainList をクエリ内に直接埋め込む。
8. ページング対応
APIの1回の取得件数上限(100件)を超える場合のページング処理。
// 1ページ分を取得する関数
GetPage = (start as number) as list =>
Json.Document(Web.Contents(
"https://api.example.com/events/",
[
Headers=[#"X-API-Key"= "YOUR_API_KEY"],
Query=[
subdomain = P1,
count = "100",
start = Number.ToText(start)
]
]
))[events],
// 1回目のAPIコールで総件数を確認
ソース1 = Json.Document(Web.Contents(...)),
総件数 = ソース1[results_available],
// 必要なページ数を計算
ページ数 = Number.RoundUp(総件数 / 100),
// 各ページのstartパラメーター値のリストを生成
Starts = List.Generate(
() => 1,
each _ <= (ページ数 - 1) * 100 + 1,
each _ + 100
),
// 全ページのイベントを取得して1つのリストに結合
全イベント = List.Combine(List.Transform(Starts, GetPage)),注意
Power BI サービスでは動的な start パラメーターがあるためページングと動的クエリ制限が相性が悪い。100件以内の場合はページングなしで設計し、超えた場合に警告を出す方が現実的。
// 100件超えた場合の警告
件数チェック = if List.Count(SubdomainList) > 100 then
error "SubdomainList が100件を超えています(現在 " & Number.ToText(List.Count(SubdomainList)) & " 件)。ページング対応が必要です。"
else
SubdomainList,connpass API v2 では results_available および start パラメーターが正しく動作しない不具合が確認されています。
ドキュメントの定義では results_returned は「含まれる検索結果の件数」、results_available は「検索結果の総件数」とされています。
実際の動作(不具合):
count=100, start=1の場合、results_availableは総件数ではなくcountと同じ 100 を返すcount=10, start=1の場合も同様にresults_availableは 10 を返すcount=100, start=101の場合、results_returnedは次の100件ではなく 0 を返すcount=10, start=2の場合、results_returnedは全体の2件目から10件ではなく、count=10 で絞った結果の2件目から9件目となり 9 を返す
本質的な問題: count パラメーターが「取得件数」ではなく「検索結果のフィルター件数」として機能しており、start パラメーターがその絞られた結果に対して適用されているため、ページングが根本的に機能しない状態です。
API v1 との比較: v1 では count=1 の場合でも results_available に総件数(例:91)が返されており正常にページングが機能していました。v1・v2 ともにドキュメントの定義は同じであるため、v2 の明確な不具合と判断されます。
現実的な対応策: 各サブドメインの年間イベント数が100件以内であれば現状のコードで全件取得可能です。100件を超える場合は connpass の修正を待つか、別の取得方法を検討する必要があります。
9. 複数のAPIソースを結合する
connpass と Doorkeeper など異なるAPIのデータを同じ列名で結合する。
// connpass テーブルと Doorkeeper テーブルを結合
最終テーブル = Table.Combine({connpassテーブル, DoorkeeperTable})ポイント
- 列名を統一する(例:
accepted、public_url、name) idなど型が異なる場合はText.From()でテキスト型に統一する
10. Dataflow について
Dataflow の役割
Power BI の Dataflow は ETL(Extract・Transform・Load)に相当する。
| ETL | 内容 | Dataflow での役割 |
|---|---|---|
| Extract | データを抽出 | 外部APIからデータを取得 |
| Transform | データを変換 | 列の選択・名前変更・型変換など |
| Load | データを読み込む | Power BI Desktop にデータを提供 |
Dataflow Gen1 vs Gen2
| Gen1 | Gen2 | |
|---|---|---|
| Power BI Pro で使える | ✅ | ❌(Fabric Premium が必要) |
| 計算されたテーブル | ❌(Premium必要) | ✅ |
| 外部API(匿名認証) | ❌ 制限あり | 未検証 |
結論
現時点では Power BI Desktop + Power BI サービス(pbix アップロード) が最も確実。
11. Power BI ダッシュボードのTips
日付の階層化を防ぐ
日付型の列が自動的に年・四半期・月・日に階層化される場合:
方法①:「ファイル」→「オプション」→「データの読み込み」→「自動日付/時刻」のチェックを外す
方法②:M言語で日付を YYYY-MM 形式のテキスト型に変換する
年月 = Text.From(Date.Year(...)) & "-" & Text.PadStart(Text.From(Date.Month(...)), 2, "0")月の並び順が正しくない場合
テキスト型の 年月 列は文字列順で並ぶため、数値型の並べ替え列を追加する。
年月数値 = Date.Year(...) * 100 + Date.Month(...)Power BI Desktop の「列ツール」→「列で並べ替え」→「年月数値」を選択。
DAX メジャーの例
// イベント数
イベント数 = COUNTROWS('テーブル名')
// 申込人数合計
申込人数合計 = SUM('テーブル名'[accepted])
// ユニーク支部数(同じ月に同じ支部が複数回開催しても1)
ユニーク支部数 = DISTINCTCOUNT('テーブル名'[subdomain])12. connpass API v2 メモ
- エンドポイント:
https://connpass.com/api/v2/events/ - 認証:
X-API-Keyヘッダー - アクセス制限:1秒間に1リクエスト
- 1回の最大取得件数:100件
- 主なパラメーター:
subdomain、count、order、ym - ⚠️ ページング不具合あり(2026年5月時点):
results_availableが総件数ではなくcountと同じ値を返す。詳細はセクション8を参照。
13. Doorkeeper API メモ
- エンドポイント:
https://api.doorkeeper.jp/groups/{group}/events - 認証:
Authorization: Bearer YOUR_TOKENヘッダー - 1回の取得件数:25件(ページネーション必要)
- 主なパラメーター:
sort、since、until、page