第5回からの続きになります。
日本政府観光局が公開している訪日外客数のデータを使って、Power BI Desktop や Excel、Power BI Service でインバンドのインサイトを探してみよう、という試みの第6回目です。
前回でフィルーターオプションと同じ操作性を持つ機能を使って不要な行を取り除き、必要な行のみを残しました。今回は「列の操作」を中心にご紹介します。
前回、[Column2] 列の見出し行(タイトル)をダブルクリックして [国名] に変更し、第1列の [Name] を同じく [年] に変更しました。

ところで、その横の列が [5月] になっていることに違和感を感じた人も少なくないはずです。その並びは、[5月] [伸率] [6月] [伸率_1] [7月]・・・と続き、[9月] [伸率_4] [1月] [10月] [伸率_5] [11月] ・・・となりました。
この順序は、1行目を見出し行にする前の ColumnX の [X] が原因です。

後に国名となるカラムの名前は [Column1] で、[5月] のカラム名は [Column10] です。[9月] は [Column18] で、その横の伸率は [Column19]、そして [1月] が [Column2] です。この ColumnX の数値 [X] の順番で並んでしまっているのです。1,2,3,4・・・ではなく、1,10,11,12・・・,2,20,21,22・・・ですね。
1月、2月、3月 ~と並べ替えたくなりますが、今回の場合、最後の処理で 「列のピボット解除」 を行って、[月] の列をつくり、その列のデータとして月を入れるので、途中で1月、2月~のように並べ替える必要はありません。
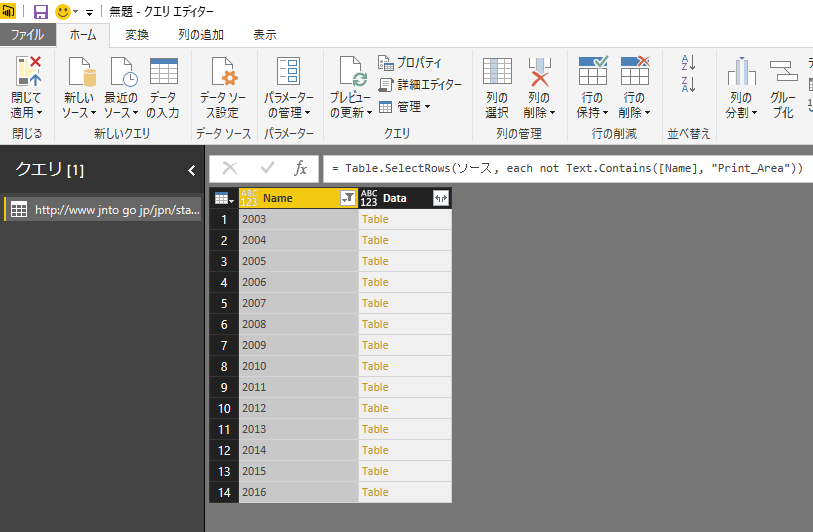
第1列の [Name] を [年]に、第2列の [Column2] を [国名] に変更したら、次は必要な列を残します。不要な列の削除の方法は2つあって、1つはその通りのまま「不要な列をすべて選択して削除する」です。一方で必要な列は [年] と [国名] と [1月] から [12月] までの [月] の列だけなので、それらをすべて選択して [他の列の削除] を選ぶことで、不要な列の削除が可能です。というより、必要な列のみを明示的に指定して残す、と言ったほうがいいでしょう。
Ctrlキーを押しながら、列名をクリックすると、複数選択が可能になります。選択された状態で、右クリックのコンテキストメニューから [他の列の削除] を選べば、選択している以外の列が削除されます。

[列の削除] を選ぶか、[他の列の削除] を選ぶかは、元のデータがどのように追加・変更される可能性が高いかで変わります。
個人的な経験談からすると、Power Query を使い始めた当初は削除する列を選択して [列の削除] を行っていました。ところが、新しいデータに不要な列がたまたま追加されたため、削除する列を明示的に指定しているこの方法では、追加された不要列は削除されずエラーになりました。
必要な列が「変化する」ものではないので、この場合は、必要な列をすべて「指定」して、その他の列を削除する指定方法が最も「再利用に適した」方法でした。
訪日外客数のデータで、必要な列だけを残すと以下のようになります。

この [列のピボット解除] の考え方が、もしかしたら「難しい」と感じている人もいるかもしれません。
というのも、非常に残念ながら Excel 入門的なトレーニングで、最初の勉強用の Excel の表として「クロス集計表=ピボットテーブル」を入力するための表として紹介する教材が多いからです。

このような縦にも横にもデータの条件を入れて、そのクロスした位置(セル)にすべての条件を満たす数値を入れる表を「クロス集計表」といいます。たとえば、C2のセルは、「支店が東京で、担当が山田で、4月の数値という条件を満たす合計は 38」という意味です。
人間が見るにはとても見やすい表なので、まずは、空のクロス集計表を作り、罫線をきれいに引いて(罫線の練習)、小計には SUM 関数をつかったり、SUBTOTAL 関数を紹介したり(関数の練習)、見出しセルでは書式の変更でフォントや位置を変えたり、といったことをする教材です。
ただし、これは人間が見やすい「最終形の表」であり、いわゆる「ピポットテーブル」としての「結果の表」です。本来この結果の表を作成するための「元の表」は以下のような、リスト形式またはテーブル形式のようなデータでなければいけません。

クロス集計表は「結果の表」であり、人間が見やすいように「修飾された表」です。クロス集計表に新しい支店や、新しい担当者、月のデータを追加するのは容易ではありません。それを苦労して修正しているケースを見ることもありますが、追加するデータはリスト・テーブル形式の「追加行」として追加し、このテーブルを元にしてクロス集計表を作る手順が、最も簡単で、最も正確で、最も間違いがない方法です。
もっと言えば、実際のデータはさらに細分化されている場合がほとんどです。
支店が東京で、担当が山田で、月は4月で、製品はAの売上が10、製品のBの売上が8、製品のCの売上が15、製品Dの売上が15で、合計が 38 といった感じです。SUMIFSの関数の題材としては面白いと思いますが、データ分析をするための「元の表」はクロス集計表ではなく、リスト・テーブル形式の表でなければなりません。
今回の題材である日本政府環境局さんのデータは、この「クロス集計表」です。残念ながら、このクロス集計表のままでは、さらなるデータ分析が難しいのです。
そして、このクロス集計表は「人間にとって見やすい」表であり、かつ「印刷に向いている」表でもあるため、官公庁が Web で公開・提供しているデータはクロス集計表であることが多いのも事実です。
このようなクロス集計表をリスト・テーブル形式の表に変換する機能を Power Query / 取得と変換は持っています。それが [変換] タブの [任意の列] グループにある [列のピボットの解除] です。

必要な列を残すときの考え方に似ていて、「解除したい列」を選択して行うか、「解除したくない列」を選択して「他の列を解除する」かを選ぶことができます。
ピボットを解除した表は以下になります。

第3列の [属性] は見出しの名前を [月] に変更し、第4列の [値] は [訪日外客数] に変更します。
この列の操作ではあと2つの変換を行います。まず、簡単なものは、 数値のデータである [訪日外客数] の列を、「数値である」設定をします。
列見出しのアイコンは、その列のデータの種類を表します。[訪日外客数] は実は数値なのか、テキストなのかわからない状態の [?] アイコンです。このアイコンをクリックすると変換データのタイプが表示されるので [整数] を選びます。

アイコンが [123] に変わり、3桁カンマがなくなります。これで計算が可能な「数値」になりました。
この型の変換は、[変換] タブの [任意の列] グループの [データ型の検出] でも可能です。この場合は自動的に型を検出し設定してくれます。
次に、[月] 列のデータが 4月、5月・・・なのであれば、[年]列のデータも 2003年、2004年とするか、[年]、[月] 両方とも数字にしたいところです。 最終的には、Excel において日付のデータは「シリアル値」として持ちたいところです。テキストか、数字かの、どちらかに揃えておいて、最後にはシリアル値にしておきます。
今回は [年] のデータに文字列の「年」を加えて、2003 を 2003年 にしてみます。
[年] の列を選択し、[変換] タブの [テキストの列] グループの [書式] の [サフィックスの追加] を選択します。
ダイアログが表示されるので、追加する「年」を入力します。

[OK] を押すと、[年] の列のデータすべてに「年」の文字列が追加されます。かつ、この列のデータはアイコンが [ABC] と示すようにテキストとして認識されます。

最後に、[年] と [月] の列のデータから、[年月] という、最終的に「シリアル値」になるデータ列を追加します。
[列の追加] タブの [カスタム列の追加] コマンドをクリックすると「カスタム列の追加」ダイアログが表示されます。
新しい列名には「年月」を入れ、カスタム列の式: には以下を入力します。
=Date.FromText([年]&[月])

[OK]を押すと、以下のように新しい列が追加され、年月のデータが作成されます。

年月日として「1日」が既定値になりました。データ型は日付です。
さきの「カスタム列の追加」で使った Date.FromText という関数は、Power Query Formula Language (PQFL) と呼ばれるものですが、別名称があり、「M言語」とも呼ばれます。
https://msdn.microsoft.com/en-us/library/mt211003.aspx
Date.FromText は日付を表す文字列から日付型のデータを作成するM言語の関数です。
Power Query / 取得と変換においてはこの「M言語」の知識が必要になる場面が出てきます。ただし、Excel のワークシート関数のような頻度で使うものではないと思います。(もしそうだとしたら、かなり苦行になります(笑) 理由は後ほど。)
これまでのクエリ エディターの拡張や、[詳細エディター]での入力支援の「無さ」から考えると、M言語を直接記述して何かやる、というより、リボンのコマンドを選択して、その順番を記録して、「適用したステップ」と fx の数式バーで修正する方向に行くような感じがします。
ここまでの作業で、データを取得して、必要な変換はすべて終わっています。
次回は、最後のほうで触れた M言語について紹介したいと思います。その後で、このデータを使って、訪日外客数のデータを利用した分析やレポートを作っていきたいですね。
では、次回をお楽しみに。
[PR] M言語(Power Query Formula Language)について書いている書籍はコレ!
日本政府観光局が公開している訪日外客数のデータを使って、Power BI Desktop や Excel、Power BI Service でインバンドのインサイトを探してみよう、という試みの第6回目です。
前回でフィルーターオプションと同じ操作性を持つ機能を使って不要な行を取り除き、必要な行のみを残しました。今回は「列の操作」を中心にご紹介します。
前回、[Column2] 列の見出し行(タイトル)をダブルクリックして [国名] に変更し、第1列の [Name] を同じく [年] に変更しました。

ところで、その横の列が [5月] になっていることに違和感を感じた人も少なくないはずです。その並びは、[5月] [伸率] [6月] [伸率_1] [7月]・・・と続き、[9月] [伸率_4] [1月] [10月] [伸率_5] [11月] ・・・となりました。
この順序は、1行目を見出し行にする前の ColumnX の [X] が原因です。

後に国名となるカラムの名前は [Column1] で、[5月] のカラム名は [Column10] です。[9月] は [Column18] で、その横の伸率は [Column19]、そして [1月] が [Column2] です。この ColumnX の数値 [X] の順番で並んでしまっているのです。1,2,3,4・・・ではなく、1,10,11,12・・・,2,20,21,22・・・ですね。
1月、2月、3月 ~と並べ替えたくなりますが、今回の場合、最後の処理で 「列のピボット解除」 を行って、[月] の列をつくり、その列のデータとして月を入れるので、途中で1月、2月~のように並べ替える必要はありません。
(1) 必要な列を選択して [他の列の削除]
第1列の [Name] を [年]に、第2列の [Column2] を [国名] に変更したら、次は必要な列を残します。不要な列の削除の方法は2つあって、1つはその通りのまま「不要な列をすべて選択して削除する」です。一方で必要な列は [年] と [国名] と [1月] から [12月] までの [月] の列だけなので、それらをすべて選択して [他の列の削除] を選ぶことで、不要な列の削除が可能です。というより、必要な列のみを明示的に指定して残す、と言ったほうがいいでしょう。
Ctrlキーを押しながら、列名をクリックすると、複数選択が可能になります。選択された状態で、右クリックのコンテキストメニューから [他の列の削除] を選べば、選択している以外の列が削除されます。

[列の削除] を選ぶか、[他の列の削除] を選ぶかは、元のデータがどのように追加・変更される可能性が高いかで変わります。
個人的な経験談からすると、Power Query を使い始めた当初は削除する列を選択して [列の削除] を行っていました。ところが、新しいデータに不要な列がたまたま追加されたため、削除する列を明示的に指定しているこの方法では、追加された不要列は削除されずエラーになりました。
必要な列が「変化する」ものではないので、この場合は、必要な列をすべて「指定」して、その他の列を削除する指定方法が最も「再利用に適した」方法でした。
訪日外客数のデータで、必要な列だけを残すと以下のようになります。

(2) 列のピボットを解除する
この [列のピボット解除] の考え方が、もしかしたら「難しい」と感じている人もいるかもしれません。
というのも、非常に残念ながら Excel 入門的なトレーニングで、最初の勉強用の Excel の表として「クロス集計表=ピボットテーブル」を入力するための表として紹介する教材が多いからです。

このような縦にも横にもデータの条件を入れて、そのクロスした位置(セル)にすべての条件を満たす数値を入れる表を「クロス集計表」といいます。たとえば、C2のセルは、「支店が東京で、担当が山田で、4月の数値という条件を満たす合計は 38」という意味です。
人間が見るにはとても見やすい表なので、まずは、空のクロス集計表を作り、罫線をきれいに引いて(罫線の練習)、小計には SUM 関数をつかったり、SUBTOTAL 関数を紹介したり(関数の練習)、見出しセルでは書式の変更でフォントや位置を変えたり、といったことをする教材です。
ただし、これは人間が見やすい「最終形の表」であり、いわゆる「ピポットテーブル」としての「結果の表」です。本来この結果の表を作成するための「元の表」は以下のような、リスト形式またはテーブル形式のようなデータでなければいけません。

クロス集計表は「結果の表」であり、人間が見やすいように「修飾された表」です。クロス集計表に新しい支店や、新しい担当者、月のデータを追加するのは容易ではありません。それを苦労して修正しているケースを見ることもありますが、追加するデータはリスト・テーブル形式の「追加行」として追加し、このテーブルを元にしてクロス集計表を作る手順が、最も簡単で、最も正確で、最も間違いがない方法です。
もっと言えば、実際のデータはさらに細分化されている場合がほとんどです。
支店が東京で、担当が山田で、月は4月で、製品はAの売上が10、製品のBの売上が8、製品のCの売上が15、製品Dの売上が15で、合計が 38 といった感じです。SUMIFSの関数の題材としては面白いと思いますが、データ分析をするための「元の表」はクロス集計表ではなく、リスト・テーブル形式の表でなければなりません。
今回の題材である日本政府環境局さんのデータは、この「クロス集計表」です。残念ながら、このクロス集計表のままでは、さらなるデータ分析が難しいのです。
そして、このクロス集計表は「人間にとって見やすい」表であり、かつ「印刷に向いている」表でもあるため、官公庁が Web で公開・提供しているデータはクロス集計表であることが多いのも事実です。
このようなクロス集計表をリスト・テーブル形式の表に変換する機能を Power Query / 取得と変換は持っています。それが [変換] タブの [任意の列] グループにある [列のピボットの解除] です。

必要な列を残すときの考え方に似ていて、「解除したい列」を選択して行うか、「解除したくない列」を選択して「他の列を解除する」かを選ぶことができます。
ピボットを解除した表は以下になります。

(3) データ型とデータの変換
第3列の [属性] は見出しの名前を [月] に変更し、第4列の [値] は [訪日外客数] に変更します。
この列の操作ではあと2つの変換を行います。まず、簡単なものは、 数値のデータである [訪日外客数] の列を、「数値である」設定をします。
列見出しのアイコンは、その列のデータの種類を表します。[訪日外客数] は実は数値なのか、テキストなのかわからない状態の [?] アイコンです。このアイコンをクリックすると変換データのタイプが表示されるので [整数] を選びます。

アイコンが [123] に変わり、3桁カンマがなくなります。これで計算が可能な「数値」になりました。
この型の変換は、[変換] タブの [任意の列] グループの [データ型の検出] でも可能です。この場合は自動的に型を検出し設定してくれます。
次に、[月] 列のデータが 4月、5月・・・なのであれば、[年]列のデータも 2003年、2004年とするか、[年]、[月] 両方とも数字にしたいところです。 最終的には、Excel において日付のデータは「シリアル値」として持ちたいところです。テキストか、数字かの、どちらかに揃えておいて、最後にはシリアル値にしておきます。
今回は [年] のデータに文字列の「年」を加えて、2003 を 2003年 にしてみます。
[年] の列を選択し、[変換] タブの [テキストの列] グループの [書式] の [サフィックスの追加] を選択します。
ダイアログが表示されるので、追加する「年」を入力します。

[OK] を押すと、[年] の列のデータすべてに「年」の文字列が追加されます。かつ、この列のデータはアイコンが [ABC] と示すようにテキストとして認識されます。

(4) 新しい列を追加してシリアル値のデータを作成する
最後に、[年] と [月] の列のデータから、[年月] という、最終的に「シリアル値」になるデータ列を追加します。
[列の追加] タブの [カスタム列の追加] コマンドをクリックすると「カスタム列の追加」ダイアログが表示されます。
新しい列名には「年月」を入れ、カスタム列の式: には以下を入力します。
=Date.FromText([年]&[月])

[OK]を押すと、以下のように新しい列が追加され、年月のデータが作成されます。

年月日として「1日」が既定値になりました。データ型は日付です。
さきの「カスタム列の追加」で使った Date.FromText という関数は、Power Query Formula Language (PQFL) と呼ばれるものですが、別名称があり、「M言語」とも呼ばれます。
https://msdn.microsoft.com/en-us/library/mt211003.aspx
Date.FromText は日付を表す文字列から日付型のデータを作成するM言語の関数です。
Power Query / 取得と変換においてはこの「M言語」の知識が必要になる場面が出てきます。ただし、Excel のワークシート関数のような頻度で使うものではないと思います。(もしそうだとしたら、かなり苦行になります(笑) 理由は後ほど。)
これまでのクエリ エディターの拡張や、[詳細エディター]での入力支援の「無さ」から考えると、M言語を直接記述して何かやる、というより、リボンのコマンドを選択して、その順番を記録して、「適用したステップ」と fx の数式バーで修正する方向に行くような感じがします。
ここまでの作業で、データを取得して、必要な変換はすべて終わっています。
次回は、最後のほうで触れた M言語について紹介したいと思います。その後で、このデータを使って、訪日外客数のデータを利用した分析やレポートを作っていきたいですね。
では、次回をお楽しみに。
[PR] M言語(Power Query Formula Language)について書いている書籍はコレ!